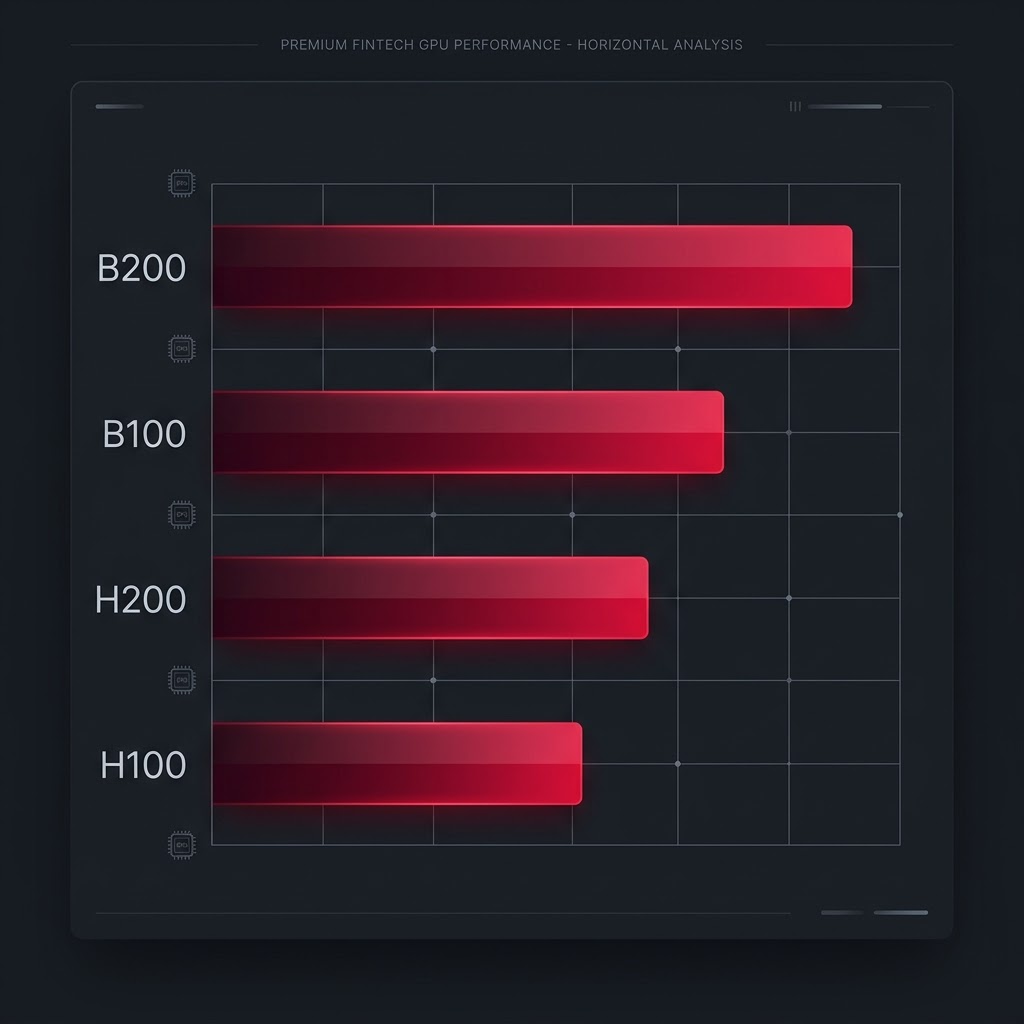
NVIDIA's most powerful data centre GPU. The B200 integrates two Blackwell dies in a single module, delivering unprecedented memory bandwidth and compute density for frontier model training and ultra-large inference workloads.

The Blackwell B100 delivers a decisive leap in compute efficiency over Hopper, with native FP4 tensor cores and double the memory bandwidth of the H100 — purpose-built for large-scale AI training and high-throughput inferencing.

The H200 upgrades NVIDIA's battle-proven Hopper architecture with HBM3e memory — delivering 4.8 TB/s of bandwidth and 141 GB of capacity per GPU. The optimal choice for large-model inference where memory capacity is the binding constraint.

The NVIDIA H100 SXM5 remains the industry standard for production AI — trusted by global cloud providers and research labs alike. Offers a proven, well-supported platform for training, fine-tuning, and deploying transformer-based models at scale.